IA – Introduction
Qu’est-ce que l’intelligence artificielle ?
La définition la plus simple serait de dire que c’est une forme d’intelligence non humaine ou plus précisément non naturelle, l’intelligence n’étant pas le propre de l’Homme, certains insectes avec des cerveaux de quelques milliers de neurones seulement sont capables de comportement intelligent et basique à titre individuel et font parfois preuve d’intelligence encore plus évoluée en groupe, on appelle ça l’intelligence de groupe, il est intéressant de noter que mécanisme de prise de décision dans ce type d’intelligence est comparable (voire le même) que celui en fonction dans le cerveau des primates.
On peut dire que l’intelligence émerge de l’interaction entre des neurones connectés d’un groupe de neurones, même si à titre individuel chaque neurone a un comportement basique, déterministe qui
A partir de quel moment on peut dire d’un rendement (ou d’un comportement) d’une machine qu’il est intelligent ? Un automate totalement déterministe peut-il par exemple être ou paraitre comme étant intelligent ?
Pour cela un test proposé consistait à organiser un dialogue entre un humain et une machine cachée (à distance les échanges se feront par écrit sur écran), la machine répond aux questions posées par l’humain, et si celui-ci est incapable de déterminer la nature de celui qui répond (si c’est une machine ou un être humain) alors c’est une machine intelligente.
Ceci dit et même si ce test n’était réussi que si les question étaient limité à un débat sur un sujet bien déterminé et connu d’avance de la machine, d’autres tests sur des domaines très spécifiques (jeux d’échec, de Go, ..) démontrent de plus en plus une supériorité de l’intelligence de la machine à celle de l’Homme.
Qu’est-ce le Machine Learning ?
C’ est une forme d’intelligence artificielle permettant aux ordinateurs d’acquérir la capacité d’améliorer leurs performances sur une tâche spécifique grâce aux données sans avoir besoin d’être directement programmés à cet effet.
Et le Deep Learning alors ?
C’est une
forme de Machine Learning où l’apprentissage se fait à travers un réseauxde
plusieurs couches (profond) de neurones artificiels
. 
Back to the past.
Perceptron le plus vieil algorithme de Machine Learning
C’est un algorithme d’apprentissage supervisé de classifieurs binaires (séparant deux classes) du type de réseau de neurones artificiels le plus simple.

Frank Rosenblatt inventa l’algorithme en 1957, au sein du Cornell Aeronautical Laboratory. L’United States Office of Naval Research finança les recherches. Les théories cognitives de Friedrich Hayek et Donald Hebb influencèrent son apparition. Initialement, il était censé être une machine plutôt qu’un programme.
Sa première implémentation fut effectuée sous la forme d’un logiciel pour l’IBM 704, mais il a ensuite été implémenté dans une machine créée spécialement pour l’occasion baptisée Mark 1. Cette machine était conçue pour la reconnaissance d’image, et regroupait 400 photocells connectés à des neurones. Les poids synaptiques étaient encodés dans des potentiomètres, et les changements de poids pendant l’apprentissage étaient effectués par des moteurs électriques. Cette machine est l’un des tout premiers réseaux de neurones artificiels.

un perceptron à une seule couche peut uniquement séparer les classes si elles sont séparables de façon linéaire.
perceptron multicouche pouvait permettre de classifier des groupes qui ne sont pas séparables de façon linéaire.
un perceptron multicouche (ou multilayer) est un type de réseau neuronal formel qui s’organise en plusieurs couches. L’information circule de la couche d’entrée vers la couche de sortie. Au contraire un modèle monocouche ne dispose que d’une seule sortie pour toutes les entrées.

(https://www.youtube.com/watch?v=XUFLq6dKQok)
Algorithmes d’optimisation du modèles (linéaires, arbre, support vectors machines)
En 2012, lors d’une compétition organisée par ImageNet, un Neural Network est parvenu pour la première fois à surpasser un humain dans la reconnaissance d’image.
Comment fonctionne le réseau de neurones artificiels ?
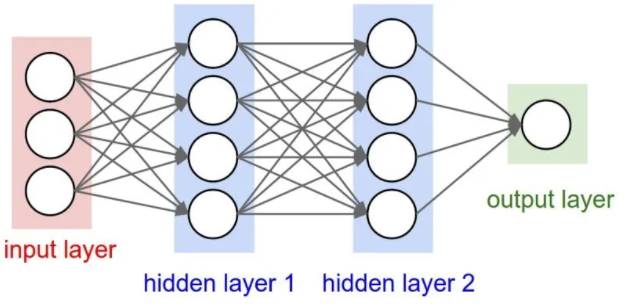
Il y a plusieurs types de réseaux de neurones
Chaque model
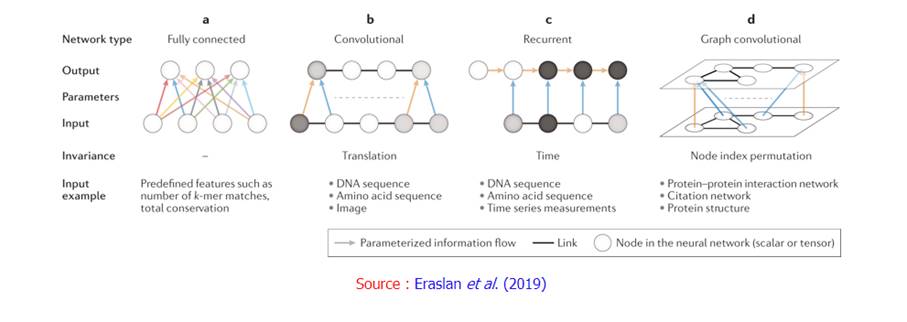
CNN : adapté au traitement des images
LSTM : Doté de mémoire et pouvant traiter des séquences de mots et d’images
Un Zoo des différents modèles
Reconnaitre un chiffre manuscrit
Un réseau de neurones complétement connectés, connections, poids par connexion
On parle de deep learning dès 2 couches de hidden layers min
28x28 ^pixel noir et blanc (0,1)= 784 neurones en input
10 neurones en sortie (0 à 9) = pourcentage de chance
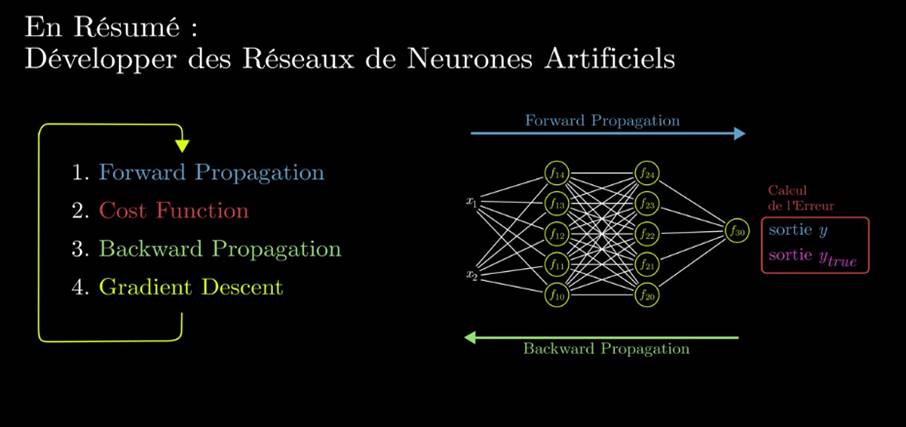
Apprentissage :
Consiste à chercher les meilleurs valeurs de poids pour les meilleurs résultats
Commencer au hasard , propager le signal,
à chaque itération comparer le résultat obtenu avec celui attendu = cout (+ élevé si + éloigné) : avec cet indice on sait quel poids a participé à cette erreur : corriger
https://www.youtube.com/watch?v=QuMabWInlAQ
Le choix de la configuration des hidden layer : par l’expérience, ajouter ou retirer une couche ou même un seul neurone peut changer complètement le comportement du réseau
( youtube 3blu1brown)
Les fonctions d’activation : tangente hyperbolique, sigmoide, rectification linéaire ..
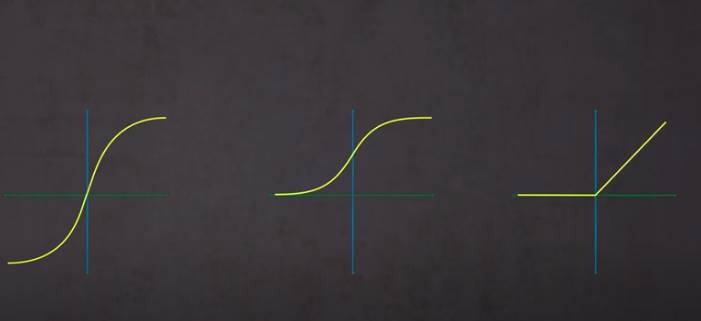
0 incactif
1 totalement actif
Sigmoid(0)=0.5
Fonction d’activation( Somme entrèes*poids + biais)
Le biai sera ajusté avec les poids durant le processus drapprentissage
On appelle ce processus feed forward
Pour le réseau rconaissance des chiffres : 13 000 poids et biais
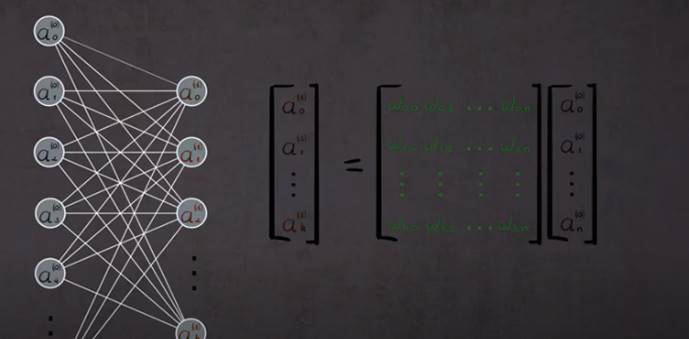
Matrice tous les poids avec les neuoes de l’autre couhce
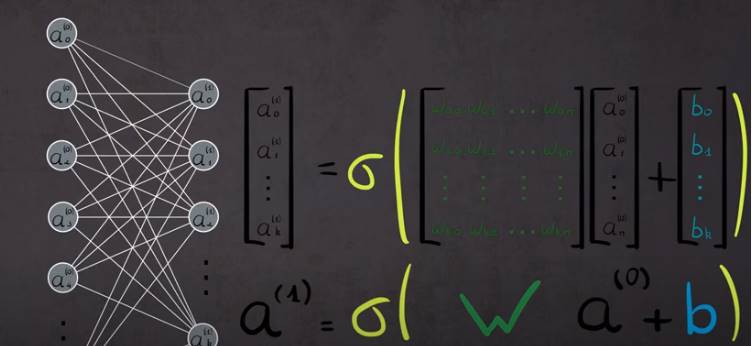
Calculer la différence entre sortie et réalité

W : le poids, ordonné : le cout
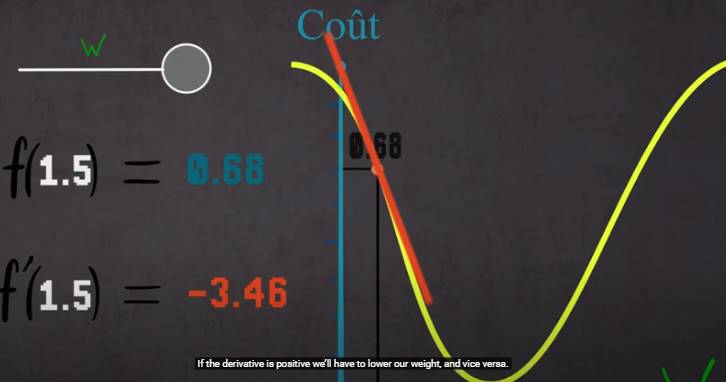
Calculer la dérivée, modifié w en fonction pour s’approcher de 0
C’est l’algorithe du gradient (Gradient descent)
Procédé de back propagation : corriger les poids qui ont participé à l’erreur) couche par couche en utilisant le gradient descent
Le deep learning est une technologie qui se greffe par-dessus de n’importe quelle domaine qui manipule de les informations
Les réseaux de neurones à résonance
L’appellation du réseau neuronal fait encore une fois référence à son fonctionnement. En effet, au sein des réseaux de neurones à résonance, l’activation de tous les neurones est renvoyée à tous les autres neurones au sein du système. Ce renvoi provoque des oscillations, d’où la raison du terme résonance.
Il va sans dire que ces réseaux de neurones peuvent prendre différentes formes avec des degrés de complexité plutôt élevés. Pour aller plus loin, je vous invite à vous intéresser à la Mémoire Associative Bidirectionnel qui permet d’associer deux informations de natures différentes ou encore le modèle ART (Adaptative Resonance Theory) qui fait interagir une information contextuelle avec la connaissance que l’on a déjà pour identifier ou reconnaître des objets.
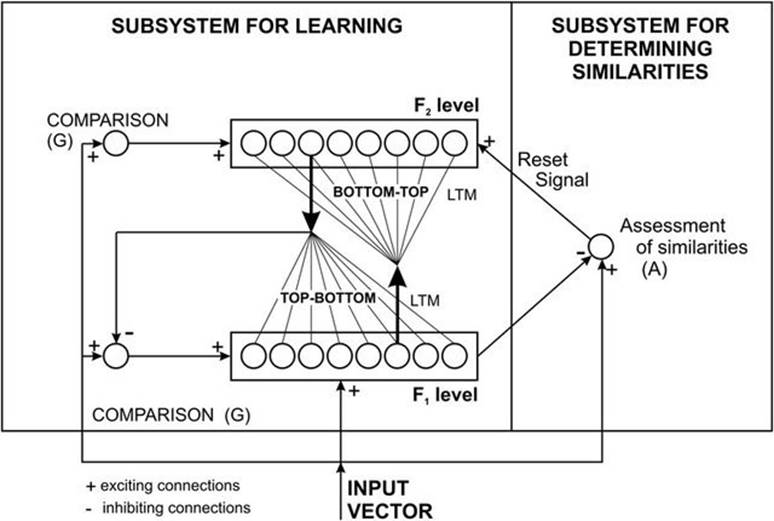
source : https://www.researchgate.net/figure/The-structure-of-the-adaptive-resonance-theory-using-the-binary-vector-input-form-ART-1_fig13_220306695
Mais alors, qu'est-ce que le Deep Learning ?
L’apprentissage profond (deep learning) est une notion issue du fait que les réseaux neurones disposaient de plus en plus de couches cachées et que le nombres élevés de couches devenait une source de problèmes. En effet, à partir d’un nombre de couches, le réseau neuronal n’était plus capable d’assimiler les informations et d’apprendre correctement.
Des solutions ont été apportées à ces problèmes et les réseaux de neurones sont de plus en plus dotées de couches multiples et capables d’apprendre. Tous ces types de réseaux de neurones peuvent être regroupés sous la notion « deep learning ».
VERS UNE TROISIÈME GÉNÉRATION DES RÉSEAUX DE NEURONES POUR LE MACHINE LEARNING : UNE INTRODUCTION AUX « SPIKING NEURAL NETWORKS »
La troisième génération des réseaux de neurones dénommée « spiking neural networks » vise à rapprocher la neuroscience et le Machine Learning. L’idée consiste à représenter les procédures biologiques différentes capables de traiter des événements ponctuels au lieu d’événements à valeur continue, c’est-à-dire, lorsqu’un neurone dépasse une certaine valeur, il émet un signal et la valeur retombe à son potentiel initial. C’est ce phénomène que les réseaux de neurones de troisième génération veulent saisir et prendre en considération.
Les « Spike Neuronal Networks » sont également très énergivores et ils demandent à simuler différents calculs d’équations. Dès lors, la durée de vie de l’application des réseaux de neurones demeure très incertaine sachant qu’ils existent principalement que dans le discours théorique et que les applications pratiques se font rares.
Neurone artificiel ("artificial neuron") : fonction mathématique simple qui prend en entrée un vecteur de valeurs réelles et calcule la moyenne pondérée de ces valeurs suivie d'une transformation non linéaire. Les poids sont les paramètres du neurone : ils sont appris lors de l'étape d'entraînement ou d'apprentissage.
Apprentissage profond ("deep learning") : réseaux de neurones avec plusieurs couches de neurones artificiels. La sortie d'une couche (la sortie d'un neurone) est introduite en entrée dans la couche suivante (un autre neurone) pour obtenir une plus grande flexibilité.
- Réseau de neurones "feed-forward" : classe de réseaux de neurones la plus flexible, dans laquelle chaque neurone peut avoir des poids arbitraires.
- Réseau de neurones convolutifs ("Convolutional Neural Network", CNN) : classe de réseaux de neurones dans laquelle des groupes de neurones artificiels sont examinés à travers la matrice d'entrée pour identifier des modèles invariants.
- Réseau de neurones récurrent ("Recurrent Neural Network", RNN) : architecture de réseaux de neurones avec des cycles pouvant traiter des entrées de différentes longueurs.
- Mémoire à court et long terme ("Long-Short Term Memory", LSTM) : architecture de RNN qui peut traiter des données ponctuelles uniques (par exemple une image) et des séquences complètes de données (par exemple la parole ou la vidéo).
Il existe deux principales méthodes d'apprentissage non-supervisées4 :
· Les méthodes par partitionnement telles que les algorithmes des k-moyennes ou k-médoïdes.
· Les méthodes de regroupement hiérarchique.
Liste des algorithmes d'apprentissage non supervisé[modifier | modifier le code]
· K-means clustering (K-moyenne)
· Dimensionality Reduction (Réduction de la dimensionnalité)
· Neural networks (Réseaux de neurones) / Deep Learning
· Principal Component Analysis (Analyse des composants principaux)
· Singular Value Decomposition (Décomposition en valeur singulière)
· Independent Component Analysis (Analyse en composantes indépendantes)
· Distribution models (Modèles de distribution)
· Hierarchical clustering (Classification hiérarchique)5
https://wiki.pathmind.com/unsupervised-learning
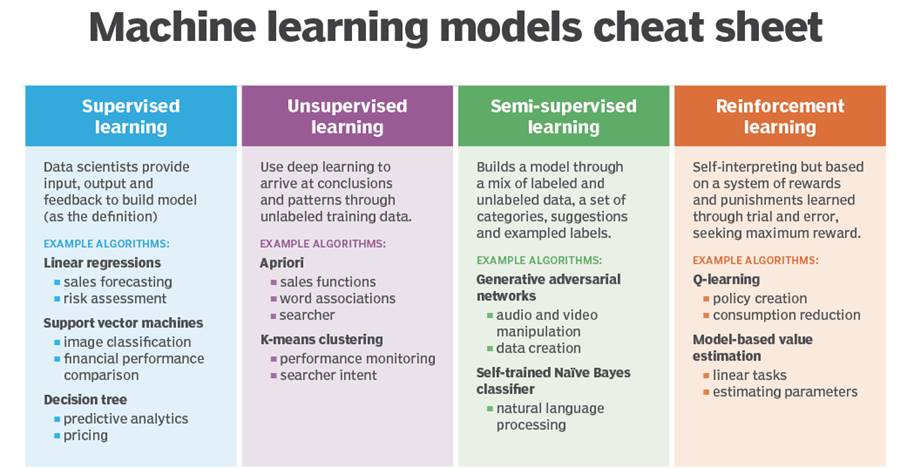
- Unsupervised learning: That thing is like this other thing. (The algorithms learn similarities w/o names, and by extension they can spot the inverse and perform anomaly detection by recognizing what is unusual or dissimilar)
- Supervised learning: That thing is a “double bacon cheese burger”. (Labels, putting names to faces…) These algorithms learn the correlations between data instances and their labels; that is, they require a labelled dataset. Those labels are used to “supervise” and correct the algorithm as it makes wrong guesses when predicting labels.
- Reinforcement learning: Eat that thing because it tastes good and will keep you alive longer. (Actions based on short- and long-term rewards, such as the amount of calories you ingest, or the length of time you survive.) Reinforcement learning can be thought of as supervised learning in an environment of sparse feedback.
https://wiki.pathmind.com/deep-reinforcement-learning
Hypothèse de Markov[modifier | modifier le code]
Dans les MDP, l'évolution du système est supposée correspondre à un processus markovien. Autrement dit, le système suit une succession d'états distincts dans le temps et ceci en fonction de probabilités de transitions. L'hypothèse de Markov consiste à dire que les probabilités de transitions ne dépendent que des n états précédents. En général, on se place à l'ordre n = 1, ce qui permet de ne considérer que l'état courant et l'état suivant.
5. How can I get started with Reinforcement Learning?
For understanding the basic concepts of RL,
· Reinforcement Learning-An Introduction, a book by the father of Reinforcement Learning- Richard Sutton and his doctoral advisor Andrew Barto. An online draft of the book is available here http://incompleteideas.net/book/the-book-2nd.html
· Teaching materialfrom David Silver including video lectures is a great introductory course on RL
· Here’s another technical tutorial on RL by Pieter Abbeel and John Schulman (Open AI/ Berkeley AI Research Lab).
· For getting started with building and testing RL agents,
· This blog on how to train a Neural Network ATARI Pong agent with Policy Gradients from raw pixels by Andrej Karpathy will help you get your first Deep Reinforcement Learning agent up and running in just 130 lines of Python code.
· DeepMind Lab is an open source 3D game-like platform created for agent-based AI research with rich simulated environments.
· Project Malmo is another AI experimentation platform for supporting fundamental research in AI.
· OpenAI gym is a toolkit for building and comparing reinforcement learning algorithms.
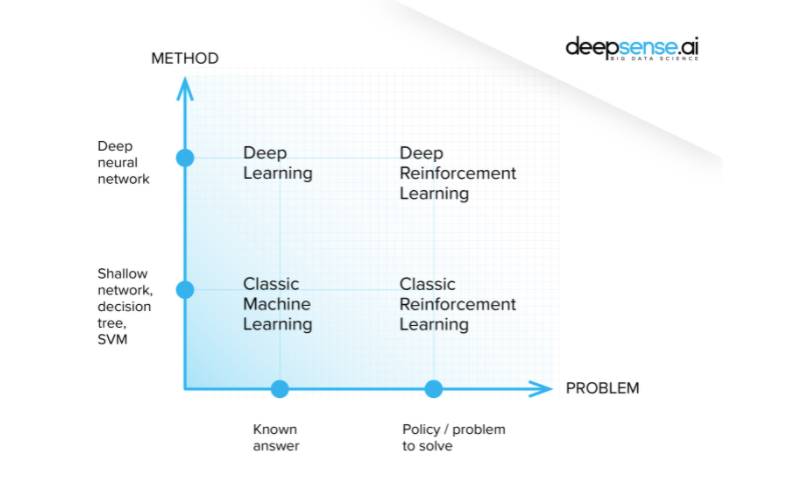
Il existe également une méthode dite de » Deep Reinforcement Learning « , où un réseau de neurones est en charge de stocker les expériences précédemment effectuées afin d’améliorer la façon dont les tâches sont effectuées.
En conclusion, ce qui distingue l’apprentissage par renforcement des autres techniques de Machine Learning est la façon dont l’agent IA est entraîné. Plutôt que d’inspecter les données qui lui sont fournies, le modèle interagit avec l’environnement et cherche des solutions pour maximiser ses récompenses…
![]()

KERAS
Keras models accept three types of inputs:
- NumPy arrays, just like Scikit-Learn and many other Python-based libraries. This is a good option if your data fits in memory.
- TensorFlow
Datasetobjects. This is a high-performance option that is more suitable for datasets that do not fit in memory and that are streamed from disk or from a distributed filesystem. (large data, GPU, perfomrmant) - Python generators that yield
batches of data (such as custom subclasses of the
keras.utils.Sequenceclass).
1/ Cgarger les données :
Des utilitaires pour charger les données du disque
tf.keras.preprocessing.image_dataset_from_directory turns image files sorted into class-specific folders into a labeled dataset of image tensors.
tf.keras.preprocessing.text_dataset_from_directory does the same for text files.
main_directory/
...class_a/
......a_image_1.jpg
......a_image_2.jpg
...class_b/
......b_image_1.jpg
......b_image_2.jpg
# Create a dataset.dataset=keras.preprocessing.image_dataset_from_directory(
'path/to/main_directory',batch_size=64,image_size=(200,200), class_names=['class_a', 'class_b'])
# For demonstration, iterate over the batches yielded by the dataset.fordata,labelsindataset:
print(data.shape)# (64, 200, 200, 3)
print(data.dtype)# float32
print(labels.shape)# (64,)
print(labels.dtype)# int32
Ou depuis un text dataset=keras.preprocessing.text_dataset_from_directory(
'path/to/main_directory',batch_size=64)
# For demonstration, iterate over the batches yielded by the dataset.fordata,labelsindataset:
print(data.shape)# (64,)
print(data.dtype)# string
print(labels.shape)# (64,)
print(labels.dtype)# int32
2/ Process des données
Ça doit idéalement faire partie du model ML (Tokenie=zer les stings, featers, Rescale data … etc
The
ideal model should expect as input something as close as possible to raw data:
an image model should expect RGB pixel values in the [0,
255] range, and a text model should accept
strings of utf-8 characters
preprocessing layers :
- Vectorizing raw strings of text via the TextVectorization layer
- Feature normalization via the Normalization layer
- Image rescaling, cropping, or image data augmentation
API
The main idea is that a deep learning model is usually a directed acyclic graph (DAG) of layers. So the functional API is a way to build graphs of layers.
API
Introduction
The Keras functional API is a way
to create models that are more flexible than the tf.keras.Sequential API.
The functional API can handle models with non-linear topology, shared layers,
and even multiple inputs or outputs.
The main idea is that a deep learning model is usually a directed acyclic graph (DAG) of layers. So the functional API is a way to build graphs of layers.
Training, evaluation, and inference
work exactly in the same way for models built using the functional API as
for Sequential models.
SCIKIT LEARN
4 fonctions sur tous les modèles
