Machine Learning
Scikit-Learn, PyTorch, TensorFlow
AIoT: Computer Vision
ntroduction
Les librairies d'apprentissage automatique
Nous avons vu dans le tuoriel 01 le code source en python d'un réseau de neurones simple qui illutre le principe d'apprentissage automatique ou Machine Learning. Nous allons voir dans ce tuto l'utilisation des librairies open source pour construire le même RN puis pour des utilisations plus pratiques comme la reconaissance (classification) des images.
Nous prenons à titre d'exemple les librairies scikit-learn, pytorch et tensorflow.
Nous allons utiliser un RN entrainé de reconaissance d'objets qui sera adapté dans le prochain tuto pour un uage AIoT

Scikit-Learn
Scikit-learn est une bibliothèque libre Python destinée à l'apprentissage automatique. Elle est développée par de nombreux contributeurs, notamment dans le monde académique par des instituts français d'enseignement supérieur et de recherche comme l'Inria et Télécom ParisTech.
Elle propose :
- Une synthaxe simple et intuitive
- Des outils simple et efficaces pour le data mining et l'analyse de donnée
- Une implémentation d'un grand nombre de modèles de machine learning
- Des fonctions pour traiter des problèmes connexes (préparation de données, sélection de modèles ...)
Les fonctions sont construites sur NumPy, SciPy (fonctions de calcul numérique sur l'opimisation, l'intégration, l'algèbre linéaire, les probabilités ...) et matplotlib (affichage de graphes et d'images)
Architecture et Utilisation
Sur le site de documentation, les fonctions sont réparties en 6 thèmes :
- Classification
- Régression
- Clustering
- Dimensionality reduction
- Model selection
- Preprocessing
sklearn propose plusieurs modèles ML avec toujours les mêmes fonctions d'instanciation, entrainement, évalution et prédiction.
#1.Sélectionner un estimateur et préciser ses hyperparamètres
model=LenearRegression(..........)
#2. Entrainer le modèle sur les données X,y (divisés en deux tableau Numpy)
model.fit(X,y)
#3. Evaluer le model
model.score(X,y)
#4. Utiliser le model
model.prediction(X)
Ci-dessous un exemple de classification pour la reconnaisance de chiffes manuscrites (des images de 8x8 pixel)
"""
================================
Reconnaître des chiffres écrits à la main
================================
Example de la documenttaion officielle scikit-learn
utilisation d'un ensemble d'images de chiffre manuscrits
de 0 à 9.
"""
print(__doc__)
# Standard scientific Python imports
import matplotlib.pyplot as plt
# Import datasets, classifiers and performance metrics
from sklearn import datasets, svm, metrics
from sklearn.model_selection import train_test_split
###############################################################################
# Digits dataset
# --------------
#
# La digits dataset est un jeu de données composé d'images 8x8 pixel en noir et blanc
# Le ``target`` de chaque donnée désigne le chiffre présent dans l'image
#
# Note: pour des image files (e.g., 'png' files)
# charger avec `matplotlib.pyplot.imread`.
digits = datasets.load_digits()
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, label in zip(axes, digits.images, digits.target):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Training: %i' % label)
##################################################### ##############################
# Classification
# --------------
#
# Pour appliquer un classificateur sur ces données, nous devons aplatir les images, en tournant
# chaque tableau 2D de valeurs en niveaux de gris de la forme ``(8, 8)`` à la forme
# ``(64,)``. Par la suite, l'ensemble de données sera de forme
# ``(n_samples, n_features)``, où ``n_samples`` est le nombre d'images et
# ``n_features`` est le nombre total de pixels dans chaque image.
#
# Nous pouvons ensuite diviser les données en sous-ensembles d'apprentissage et de test et adapter un support
# classificateur vectoriel sur les échantillons de train. Le classificateur intégré peut
# être ensuite utilisé pour prédire la valeur du chiffre pour les échantillons
# dans le sous-ensemble de test.
#
# Applatir (flatten) l'images
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Création du classificateur ( un support vector classifier)
clf = svm.SVC(gamma=0.001)
# Répartir les données 50% entrainement et 50% pour les test
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False)
# Apprendre les digits sur les données d'apprentissage
clf.fit(X_train, y_train)
# Prediction les valeurs de l'ensemble de test
predicted = clf.predict(X_test)
###############################################################################
# Visualisation
# valeur dans le titre.
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, prediction in zip(axes, X_test, predicted):
ax.set_axis_off()
image = image.reshape(8, 8)
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title(f'Prediction: {prediction}')
###############################################################################
# :func:`~sklearn.metrics.classification_report` builds a text report showing
# the main classification metrics.
print(f"Classification report for classifier {clf}:\n"
f"{metrics.classification_report(y_test, predicted)}\n")
###############################################################################
# We can also plot a :ref:`confusion matrix ` of the
# true digit values and the predicted digit values.
disp = metrics.plot_confusion_matrix(clf, X_test, y_test)
disp.figure_.suptitle("Confusion Matrix")
print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()


Pytorch
Qu'est-ce que PyTorch ?
PyTorch est une bibliothèque basée sur Python qui facilite la création de modèles de Deep Learning et leur utilisation dans diverses applications. Mais c'est plus qu'une simple bibliothèque de Deep Learning. C'est un progiciel de calcul scientifique (comme l'indiquent les documents officiels de PyTorch).
Il s'agit d'un progiciel de calcul scientifique basé sur Python qui s'adresse à deux groupes de publics :
- 1. Un remplacement pour NumPy pour utiliser la puissance des GPU
- 2. Une plate-forme de recherche d'apprentissage en profondeur qui offre une flexibilité et une vitesse maximale
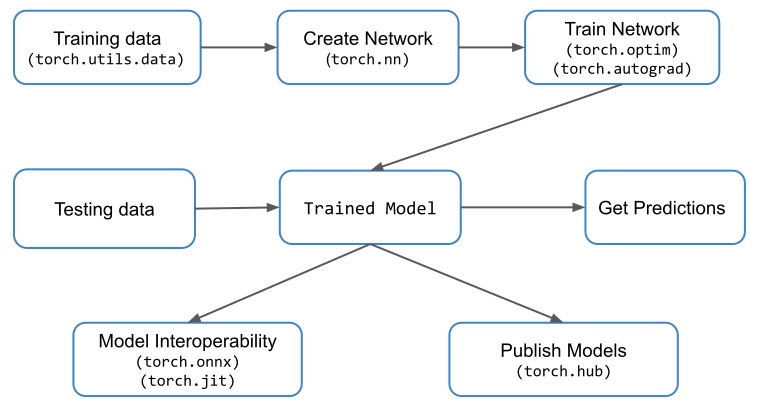
Tensor: CPU v/s GPU
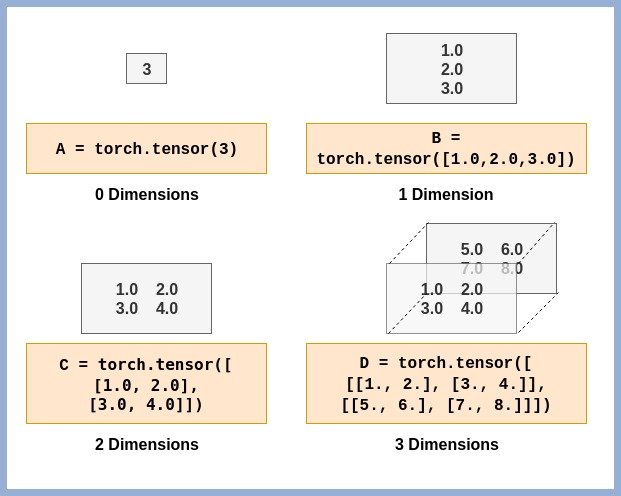
Les Tensors sont la structure de données de base utilisée dans PyTorch.
Tensor est simplement un nom fantaisiste donné aux matrices. Si vous êtes familier avec les tableaux NumPy, comprendre et utiliser les Tenseurs PyTorch sera très facile. Une valeur scalaire est représentée par un Tenseur à 0 dimension. De même, une matrice colonne/ligne est représentée à l'aide d'un Tenseur 1-D et ainsi de suite. Quelques exemples de Tensors avec différentes dimensions sont montrés pour que vous puissiez visualiser et comprendre
PyTorch a une implémentation différente de Tensor pour le CPU et pour le GPU. Chaque tenseur peut être converti en GPU afin d'effectuer des calculs massivement parallèles et rapides. Toutes les opérations qui seront effectuées sur le tenseur seront effectuées à l'aide de routines spécifiques au GPU fournies avec PyTorch.
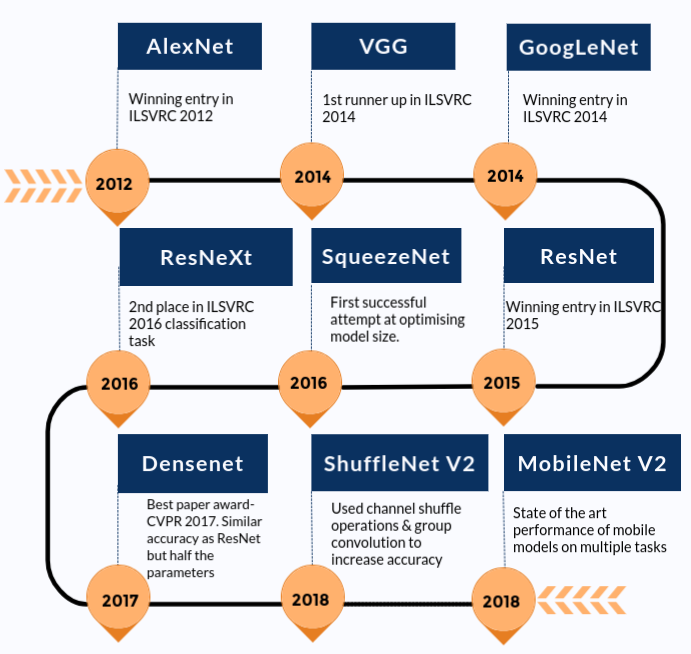
Classification d'images à l'aide de modèles pré-entraînés
Les modèles pré-entraînés sont des modèles de réseau neuronal entraînés sur de grands ensembles de données de référence comme ImageNet. La communauté Deep Learning a grandement bénéficié de ces modèles open source. De plus, les modèles pré-entraînés sont un facteur majeur pour les progrès rapides de la recherche en vision par ordinateur. D'autres chercheurs et praticiens peuvent utiliser ces modèles de pointe au lieu de tout réinventer à partir de zéro.
Vous trouverez ci-dessous une chronologie approximative de la façon dont les modèles de pointe se sont améliorés au fil du temps. Nous n'avons inclus que les modèles présents dans le package Torchvision.
Construction et entrainement d'un Modèle
Nous allons nous concentrer sur la façon d'utiliser les modèles pré-entraînés pour prédire la classe (étiquette) d'entrée, discutons également du processus impliqué dans cela. Ce processus est appelé inférence de modèle. L'ensemble du processus comprend les étapes principales suivantes.
- Lecture de l'image d'entrée
- Effectuer des transformations sur l'image. Par exemple – redimensionner, rogner au centre, normalisation, etc.
- Passe avant : utilisez les poids pré-entraînés pour connaître le vecteur de sortie. Chaque élément de ce vecteur de sortie décrit la confiance avec laquelle le modèle prédit que l'image d'entrée appartient à une classe particulière.
- Sur la base des scores obtenus (éléments du vecteur de sortie que nous avons mentionnés à l'étape 3), affichez les prédictions
Vous trouverez ci-dessous un exemple.
from torchvision import models
from torchvision import transforms
# Import Pillow
from PIL import Image
import torch
print(dir(models))
alexnet = models.alexnet(pretrained=True)
# You will see a similar output as below
# Downloading: "https://download.pytorch.org/models/alexnet-owt- 4df8aa71.pth" to /home/hp/.cache/torch/checkpoints/alexnet-owt-4df8aa71.pth
print(alexnet)
transform = transforms.Compose([ #[1]
transforms.Resize(256), #[2]
transforms.CenterCrop(224), #[3]
transforms.ToTensor(), #[4]
transforms.Normalize( #[5]
mean=[0.485, 0.456, 0.406], #[6]
std=[0.229, 0.224, 0.225] #[7]
)])
img = Image.open("c:\img\dog.jpg")
img.show()
img_t = transform(img)
batch_t = torch.unsqueeze(img_t, 0)
alexnet.eval()
out = alexnet(batch_t)
print(out.shape)
with open('venv\imagenet_classes.txt') as f:
classes = [line.strip() for line in f.readlines()]
_, index = torch.max(out, 1)
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
print(classes[index[0]], percentage[index[0]].item())
_, indices = torch.sort(out, descending=True)
print([(classes[idx], percentage[idx].item()) for idx in indices[0][:5]])
Classification d'images à l'aide de l'apprentissage par transfert dans PyTorch
Apprentissage par Transfert
Nous allons maintenant voir la classification des images dans PyTorch. Nous utiliserons un sous-ensemble de l'ensemble de données CalTech256 pour classer les images de 10 animaux. Nous passerons en revue les étapes de préparation de l'ensemble de données, d'augmentation des données, puis les étapes pour construire le classifieur.
Nous utilisons l'apprentissage par transfert pour utiliser les fonctionnalités d'image de bas niveau comme les bords, les textures, etc. Celles-ci sont apprises par un modèle pré-entraîné, ResNet50, puis formons notre classificateur pour apprendre les détails de niveau supérieur dans nos images de jeu de données comme les yeux, les jambes, etc. ResNet50 a déjà été formé sur ImageNet avec des millions d'images.
Préparation des données
Pour cet exemple nous allons préparer le jeux de données à partir de CalTech256
- Télécharger le jeu de données CalTech256
- Créez trois répertoires avec les noms train, valid et test.
- Créez 10 sous-répertoires chacun à l'intérieur du train et des répertoires de test. Les sous-répertoires doivent être nommés ours, chimpanzé, girafe, gorille, lama, autruche, porc-épic, mouffette, tricératops et zèbre.
- Déplacez les 60 premières images de l'ours dans l'ensemble de données Caltech256 vers le répertoire train/ours.
- Répétez cette étape pour chaque animal.
- Déplacez les 10 images suivantes pour l'ours dans l'ensemble de données Caltech256 vers le répertoire valid/ours.
- Répétez cette étape pour chaque animal.
- Copiez les images restantes pour ours (c'est-à-dire celles qui ne sont pas incluses dans train ou dans des dossiers valides) dans le répertoire test/bear.
- Répétez cette étape pour chaque animal.
Passons en revue les transformations que nous avons utilisées pour notre augmentation de données.
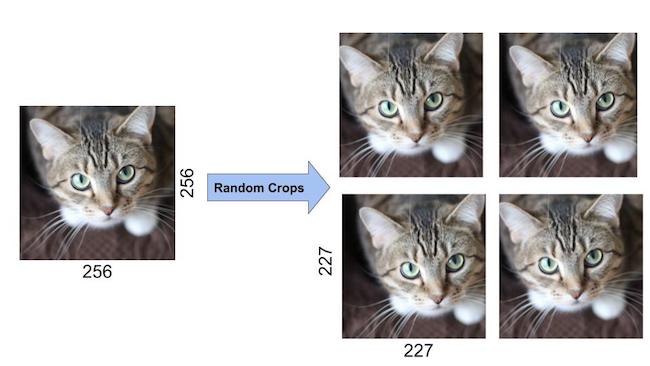
La transformation RandomResizedCrop recadre l'image d'entrée selon une taille aléatoire (dans une plage d'échelle de 0,8 à 1,0 de la taille d'origine et un rapport hauteur/largeur aléatoire dans la plage par défaut de 0,75 à 1,33). L'image recadrée est ensuite redimensionnée à 256×256.
RandomRotation fait pivoter l'image selon un angle aléatoire compris entre -15 et 15 degrés.
RandomHorizontalFlip retourne l'image horizontalement de manière aléatoire avec une probabilité par défaut de 50 %.
CenterCrop recadre une image 224×224 à partir du centre.
ToTensor convertit l'image PIL dont les valeurs sont comprises entre 0 et 255 en un tenseur à virgule flottante et les normalise dans une plage de 0 à 1, en la divisant par 255.
Normalize prend un Tensor à 3 canaux et normalise chaque canal par la moyenne d'entrée et l'écart type pour ce canal. Les vecteurs de moyenne et d'écart type sont entrés sous forme de vecteurs à 3 éléments. Chaque canal du tenseur est normalisé comme T = (T – moyenne)/(écart type)
Toutes les transformations ci-dessus sont enchaînées à l'aide de Compose.
from torchvision import models
from torchvision import transforms
# Import Pillow
from PIL import Image
import torch
print(dir(models))
alexnet = models.alexnet(pretrained=True)
# Applying Transforms to the Data
image_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
Notez que pour les données de validation et de test, nous ne faisons pas les transformations RandomResizedCrop, RandomRotation et RandomHorizontalFlip. Au lieu de cela, nous redimensionnons simplement les images de validation à 256 × 256 et recadrons le centre 224 × 224 afin de pouvoir les utiliser avec le modèle pré-entraîné. Enfin, l'image est transformée en un tenseur et normalisée par la moyenne et l'écart type de toutes les images dans ImageNet.
Chargement des données.
# Load the Data
# Set train and valid directory paths
train_directory = 'train'
valid_directory = 'test'
# Batch size
bs = 32
# Number of classes
num_classes = 10
# Load Data from folders
data = {
'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']),
'valid': datasets.ImageFolder(root=valid_directory, transform=image_transforms['valid']),
'test': datasets.ImageFolder(root=test_directory, transform=image_transforms['test'])
}
# Size of Data, to be used for calculating Average Loss and Accuracy
train_data_size = len(data['train'])
valid_data_size = len(data['valid'])
test_data_size = len(data['test'])
# Create iterators for the Data loaded using DataLoader module
train_data = DataLoader(data['train'], batch_size=bs, shuffle=True)
valid_data = DataLoader(data['valid'], batch_size=bs, shuffle=True)
test_data = DataLoader(data['test'], batch_size=bs, shuffle=True)
# Print the train, validation and test set data sizes
train_data_size, valid_data_size, test_data_size
Comme nous pouvons le voir dans l'image ci-dessus, les couches internes sont conservées les mêmes que le modèle pré-entraîné et seules les couches finales sont modifiées pour s'adapter à notre nombre de classes. Dans ce tuto nous utilisons le modèle ResNet50 pré-entraîné.
# Load pretrained ResNet50 Model
resnet50 = models.resnet50(pretrained=True)
#Lorsqu'un modèle est chargé dans PyTorch, tous ses paramètres ont leur champ requires_grad défini sur true par défaut
#Freeze model parameters
for param in resnet50.parameters():
param.requires_grad = False
Ensuite, nous remplaçons la dernière couche du modèle ResNet50 par un petit ensemble de couches séquentielles Les entrées de la dernière couche entièrement connectée de ResNet50 sont transmises à une couche linéaire. Il dispose de 256 sorties, qui sont ensuite introduites dans les couches ReLU et Dropout. Il est ensuite suivi d'une couche linéaire 256 × 10 qui a 10 sorties correspondant aux 10 classes de notre sous-ensemble CalTech.
#Change the final layer of ResNet50 Model for Transfer Learning
fc_inputs = resnet50.fc.in_features
resnet50.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 10),
nn.LogSoftmax(dim=1) # For using NLLLoss()
)
Ensuite, nous définissons la fonction de perte et l'optimiseur à utiliser pour l'entraînement. PyTorch fournit une variété de fonctions de perte. Nous utilisons la fonction de probabilité de perte négative car elle est utile pour classer plusieurs classes. PyTorch prend également en charge plusieurs optimiseurs. Nous utilisons l'optimiseur Adam. Adam est l'un des optimiseurs les plus populaires car il peut adapter le taux d'apprentissage pour chaque paramètre individuellement.
#Define Optimizer and Loss Function
loss_func = nn.NLLLoss()
optimizer = optim.Adam(resnet50.parameters())
Entrainement
L'apprentissage est effectué pour un ensemble fixe d'époques, en traitant chaque image une fois dans une seule époque. Le chargeur de données d'apprentissage charge les données par lots. Dans notre cas, nous avons donné une taille de lot de 32. Cela signifie que chaque lot peut avoir un maximum de 32 images.
Pour chaque lot, les images d'entrée sont passées à travers le modèle (aka forward pass), pour obtenir les sorties. Ensuite, la fonction loss_criterion ou fonction coût fournie est utilisée pour calculer la perte à l'aide de la vérité terrain et des sorties calculées.
Les gradients de la perte par rapport aux paramètres pouvant être entraînés sont calculés à l'aide de la fonction arrière. Notez qu'avec l'apprentissage par transfert, nous devons calculer les gradients uniquement pour un petit ensemble de paramètres qui appartiennent aux quelques couches nouvellement ajoutées vers la fin du modèle
Un appel de fonction récapitulatif au modèle peut révéler le nombre réel de paramètres et le nombre de paramètres pouvant être entraînés. L'avantage que nous avons dans cette approche est que nous n'avons désormais besoin de former qu'environ un dixième du nombre total de paramètres du modèle.

Le calcul du gradient est effectué à l'aide de l'autogradation et de la rétropropagation, en différenciant dans le graphique à l'aide de la règle de la chaîne. PyTorch accumule tous les gradients dans la passe arrière. Il est donc essentiel de les mettre à zéro au début de la boucle d'entraînement. Ceci est réalisé en utilisant la fonction zero_grad de l'optimiseur. Enfin, une fois les gradients calculés dans le passage en arrière, les paramètres sont mis à jour à l'aide de la fonction pas à pas de l'optimiseur.
La perte totale et la précision sont calculées pour l'ensemble du lot, qui est ensuite moyennée sur tous les lots pour obtenir les valeurs de perte et de précision pour toute l'époque.
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch+1, epochs))
# Set to training mode
model.train()
# Loss and Accuracy within the epoch
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(train_data_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# Clean existing gradients
optimizer.zero_grad()
# Forward pass - compute outputs on input data using the model
outputs = model(inputs)
# Compute loss
loss = loss_criterion(outputs, labels)
# Backpropagate the gradients
loss.backward()
# Update the parameters
optimizer.step()
# Compute the total loss for the batch and add it to train_loss
train_loss += loss.item() * inputs.size(0)
# Compute the accuracy
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
# Convert correct_counts to float and then compute the mean
acc = torch.mean(correct_counts.type(torch.FloatTensor))
# Compute total accuracy in the whole batch and add to train_acc
train_acc += acc.item() * inputs.size(0)
print("Batch number: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}".format(i, loss.item(), acc.item()))
Validation
Comme l'entraînement est effectué pour un plus grand nombre d'époques, le modèle a tendance à surajuster les données, ce qui entraîne de mauvaises performances sur les nouvelles données de test. Le maintien d'un ensemble de validation séparé est important, afin que nous puissions arrêter la formation au bon moment et éviter le surapprentissage. La validation est effectuée à chaque époque immédiatement après la boucle d'apprentissage. Comme nous n'avons besoin d'aucun calcul de gradient dans le processus de validation, cela se fait dans un bloc torch.no_grad().
Pour chaque lot de validation, les entrées et les labels sont transférés vers le GPU (si cuda est disponible, sinon ils sont transférés vers le CPU). Les entrées passent par la passe avant, suivie des calculs de perte et de précision pour le lot et à la fin de la boucle, pour toute l'époque.
# Validation - No gradient tracking needed
with torch.no_grad():
# Set to evaluation mode
model.eval()
# Validation loop
for j, (inputs, labels) in enumerate(valid_data_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# Forward pass - compute outputs on input data using the model
outputs = model(inputs)
# Compute loss
loss = loss_criterion(outputs, labels)
# Compute the total loss for the batch and add it to valid_loss
valid_loss += loss.item() * inputs.size(0)
# Calculate validation accuracy
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
# Convert correct_counts to float and then compute the mean
acc = torch.mean(correct_counts.type(torch.FloatTensor))
# Compute total accuracy in the whole batch and add to valid_acc
valid_acc += acc.item() * inputs.size(0)
print("Validation Batch number: {:03d}, Validation: Loss: {:.4f}, Accuracy: {:.4f}".format(j, loss.item(), acc.item()))
# Find average training loss and training accuracy
avg_train_loss = train_loss/train_data_size
avg_train_acc = train_acc/float(train_data_size)
# Find average training loss and training accuracy
avg_valid_loss = valid_loss/valid_data_size
avg_valid_acc = valid_acc/float(valid_data_size)
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
epoch_end = time.time()
print("Epoch : {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, nttValidation : Loss : {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(epoch, avg_train_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start))
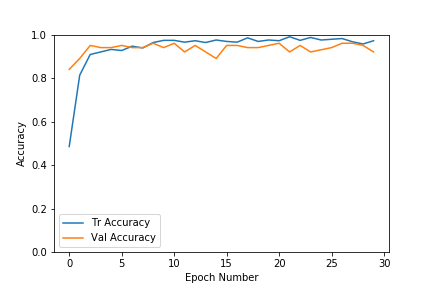
Courbe de perte pour la formation et la validation
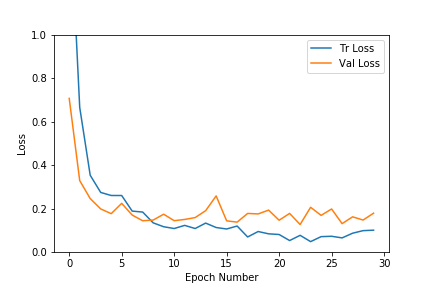
Courbe de précision pour la formation et la validationi
Comme nous pouvons le voir dans les graphiques ci-dessus, les pertes de validation et d'entraînement s'installent assez rapidement pour cet ensemble de données. La précision augmente également très rapidement jusqu'à la plage de 0,9. À mesure que le nombre d'époques augmente, la perte d'entraînement diminue davantage, entraînant un surapprentissage, mais les résultats de validation ne s'améliorent pas beaucoup. Nous avons donc choisi le modèle de l'époque qui avait une plus grande précision et une plus faible perte. Il est préférable de s'arrêter tôt pour éviter de suradapter les données d'entraînement. Dans notre cas, nous avons choisi l'époque n°8 qui avait une précision de validation de 96%.Le processus d'arrêt anticipé peut également être automatisé. Nous pouvons arrêter une fois que la perte est inférieure à un seuil donné et si la précision de validation ne s'améliore pas pour un ensemble d'époques donné.
Inférence
Une fois que nous avons le modèle, nous pouvons faire une inférence sur des images de test individuelles ou sur l'ensemble des données de test pour obtenir la précision du test. Le calcul de la précision de l'ensemble de test est similaire au code de validation, sauf qu'il est effectué sur l'ensemble de données de test. Nous avons inclus la fonction computeTestSetAccuracy dans le bloc-notes Python pour la même chose. Voyons ci-dessous comment trouver la classe de sortie pour une image de test donnée.
Une image d'entrée subit d'abord toutes les transformations utilisées pour les données de validation/test. Le tenseur résultant est ensuite converti en un tenseur à 4 dimensions et passé à travers le modèle qui génère les probabilités de log pour différentes classes. Une exponentielle des sorties du modèle nous fournit les probabilités de classe. puis nous choisissons la classe avec la probabilité la plus élevée comme classe de sortie.
Choisissez la classe avec la probabilité la plus élevée comme classe de sortie.
def predict(model, test_image_name):
transform = image_transforms['test']
test_image = Image.open(test_image_name)
plt.imshow(test_image)
test_image_tensor = transform(test_image)
if torch.cuda.is_available():
test_image_tensor = test_image_tensor.view(1, 3, 224, 224).cuda()
else:
test_image_tensor = test_image_tensor.view(1, 3, 224, 224)
with torch.no_grad():
model.eval()
# Model outputs log probabilities
out = model(test_image_tensor)
ps = torch.exp(out)
topk, topclass = ps.topk(1, dim=1)
print("Output class : ", idx_to_class[topclass.cpu().numpy()[0][0]])
Ci-dessous certains des résultats de classification sur les nouvelles données de test qui n'ont pas été utilisées dans la formation ou la validation. Les meilleures classes prédites pour les images avec leurs scores de probabilité sont superposées en haut à droite. Comme nous le voyons ci-dessous, la classe prédite avec la probabilité la plus élevée est souvent la bonne. Notez également que la classe avec la deuxième probabilité la plus élevée est souvent l'animal le plus proche en termes d'apparence de la classe réelle parmi les 9 classes restantes.


TensorFlow
Outil open source d'apprentissage automatique développé par Google
TensorFlow est une plate-forme Open Source de bout en bout dédiée au machine learning.
Elle propose un écosystème complet et flexible d'outils, de bibliothèques et de ressources communautaires permettant aux chercheurs d'avancer dans le domaine du machine learning, et aux développeurs de créer et de déployer facilement des applications qui exploitent cette technologie.
Tensorflow est la deuxième génération du système de Google Brain. La version 1.0.0 est sortie le 11 février 20178 Alors que l'implémentation de référence tourne sur un seul appareil, Tensorflow peut être lancé sur plusieurs CPU et GPU (avec des extensions optionnelles telles que CUDA ou SYCL (en) pour GPGPU)9. Tensorflow est disponible en version 64-bits pour Linux, macOS, Windows et pour les plateformes mobiles sur Android et iOS.
Son architecture flexible permet le développement sur plusieurs variétés de plateformes (CPU, GPU, TPU), allant du PC de bureaux à des clusters de serveurs et des mobiles aux dispositifs de bords.
En mai 2017, Google a annoncé qu'une couche logicielle spécifique serait créée pour le développement sur Android, Tensorflow Lite, à partir d'Android Oreo11. Il existe une version orientée vers les microcontrôleurs (anglais : Tensorflow lite for microcontrollers) et a notamment été porté sur la plateforme ARM Cortex-M et ESP3212.
